Døde laks og syntetiske respondenter

maj 19, 2026
Syntetiske respondenter er begyndt at fylde i analysebranchen. Barnet har mange navne: syntetiske paneler, syntetiske svar, digitale tvillinger. Men barnet er lige hypet, uagtet hvad vi kalder det – men hvad er det? Læs med.
Kort fortalt er syntetiske respondenter en tilgang, hvor man erstatter svar fra rigtige mennesker med et syntetisk svar, der simulerer svaret fra et menneske. Syntetiske respondenter lover hurtigere og billigere indsigter. Når noget er hurtigt og billigt er det ofte ikke af samme kvalitet. Selvom – ja, ”AI”. Men er kvaliteten god nok til at begynde at bruge i analysesammenhænge? Det prøver vi her at give et svar på.
Hvad er det egentlig? Og er det nyt?
Lad os starte lidt historisk. At udfylde manglende data i et datasæt med ”gæt” er ikke nyt. ”Statistisk imputation” har fandtes længe. Her udfylder man manglede svar i et datasæt ud fra svarene i det eksisterende data fra rigtige mennesker. Det gør man på en måde, så datasættet bevarer sine overordnede statistiske egenskaber. Der er klare antagelser og klare metoder. Syntetisk data er noget andet. Her er den typiske tilgang, at en stor sprogmodel (LLM) genererer et svar ved at udregne en række af tokens betinget af en prompt, hvor prompten typisk beskriver en persona (a la ”Du er en 50-årig mand fra Randers, der stemmer på Liberal Alliance”). Modellen genererer derefter et svar baseret på, hvad der er mest sandsynligt givet dens træningsdata om eks. midaldrende mænd fra Randers. Med gennembruddet i store sprogmodeller de seneste år er dette nyt – og et område, hvor vi hele tiden ser nye produkter og ny forskning, som undersøger styrker og begrænsninger.
Hvad skal vi være opmærksomme på, hvis vi vil bruge syntetiske respondenter?
I Epinion har vi fulgt udviklingen tæt. I starten med en vis begejstring, hvor vi blandt andet gennemførte et projekt, hvor vi testede syntetiske respondenter allerede tilbage i 2024. Men sidenhen er der kommet en del forskning på området, som gør, at vi har kombineret vores åbenhed med en mængde skepsis. Vi er ikke imod syntetisk data partout. Men vi er skeptiske overfor ukritisk begejstring som tenderer til ”AI hype”. Vi kan være nervøse for, at syntetiske respondenter kan bidrage til ”AI-slop indsigter”, som ingen reelt har brug for eller kan træffe vigtige beslutninger på baggrund af. At det bidrager til dårligere beslutningsgrundlag, ikke bedre. I Epinion er vores udgangspunkt lige nu ret enkelt:
Hvis en beslutning er vigtig nok til at kræve seriøs analyse og rådgivning, er den også for vigtig til syntetiske respondenter i deres nuværende form.
Syntetiske respondenter bliver ofte solgt på fart, pris og skalerbarhed. Og de kan producere svar hurtigt. De kan generere store mængder output på få minutter. De kan levere noget, der ligner et beslutningsgrundlag. Men det er ikke det samme som, at de leverer et datagrundlag, man trygt kan handle på.
Det, modellen ved, er ofte det, vi allerede vidste
Syntetiske respondenter er i praksis modeller, der genererer svar ud fra mønstre i eksisterende data – modellernes træningsdata. Det er sådan, modeller fungerer. De er stærke til at gengive sandsynlige sammenhænge på baggrund af det, de allerede har set. Men netop derfor har de også en indbygget svaghed: De hælder mod fortiden.
Når en population bevæger sig – på grund af en krise, et valg, en kulturel forskydning eller nye generationelle mønstre – vil modellen være tilbøjelig til at reproducere det velkendte frem for at opdage det nye. Det er et gammelkendt problem i alignment forskning kendt som distributional shifts (Christian, 2021). Men det er særligt centralt her, da de nye bevægelser ofte er præcis det, beslutningstagere er interesserede i at få øje på.
Døde laks og syntetiske respondenter
Hvis man vil forstå den metodiske risiko, er det værd at tage en omvej forbi et af forskningens mest berømte advarselseksempler. En personlig favorit, må jeg også indrømme.
I det såkaldte dead salmon-studie lagde forskere en død atlanterhavslaks i en fMRI-scanner og fandt tilsyneladende signifikant aktivitet i laksens nervesystem. En laks tænker selvfølgelig ikke efter døden. Men forskerne ville demonstrere en pointe om, at et output, der ser troværdigt ud, ikke altid er det (Benett et al. 2010).
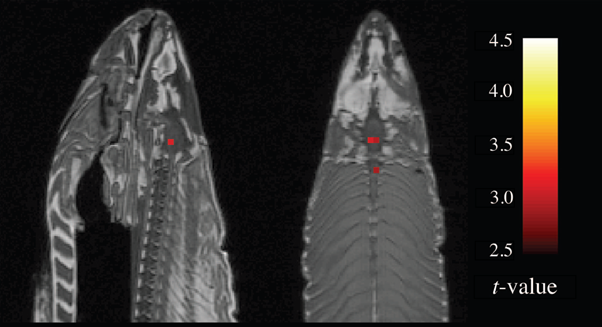
Billede af en død laks i en fMRI-scanner
I Epinion har vi testet forskellige værktøjer, der findes på markedet allerede. De fleste fortæller om netop deres validitet og netop deres nøjagtighed, som de har testet i et givet studie. Vi anlagde en ”død laks”-tilgang for at teste, om modellen ville give et “plausibelt men meningsløst svar”.
Konkret udviklede og testede vi her to kreativer, som vi skulle have feedback på – vi beskrev kreativ ét som et ”Television monitor – Smart TV w/ physical buttons” og kreativ to som ”Television monitor – Smart TV without phycical buttons”. En simpel test af to smart-TVs.
Vi valgte en målgruppe – 500 svar fra generation Z – og fik på 30 sekunder et svar: Kreativ 1: ”Television monitor – Smart TV w/ physical buttons” var bedst. På en skala fra 0-5 scorede den 2,35. Altså ikke et fantastisk fjernsyn men heller ikke det værste i verden.
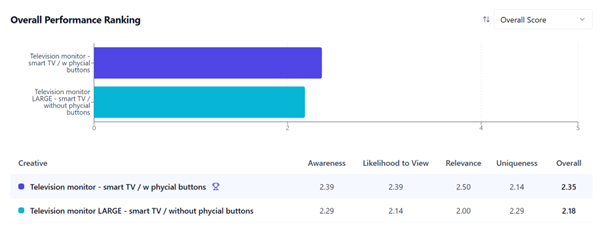
Vi fik også LLM-genererede forslag til, hvordan vi kunne forbedre vores kreativ: Baggrundsfarven var for stærk, titlen var funktionel men ikke inspirerende, og fjernsynet kunne ikke ses tydeligt nok. Den sidste del var i hvert fald rigtig. For problemet er, at vi slet ikke testede et fjernsyn. I stedet var det et meme af JC Vance. Vores version af en ”død laks”, i overført betydning, forstås. Så altså – modellen synes JC Vance-memet er et halvdårligt/halvgodt fjernsyn. Det er sjovt, men ikke noget jeg ville læne mig op ad, hvis jeg skulle tage en vigtig beslutning.

Det er den lektie, analysebranchen bør tage med sig ind i diskussionen om syntetiske respondenter. For problemet med syntetisk data er, at output ofte fremstår langt mere sikkert, meningsfuldt og anvendeligt, end det i virkeligheden er.
De glatte respondenter
Men du skal ikke bare tage vores ”død laks”-test for gode vare. Den er mere sjov end den har høj kvalitet. Heldigvis er der en masse forskere, som bruger mere tid på at lave studier, som vi kan kigge til. Grundlæggende viser forskningen i dag, at der er noget systematisk skævt ved syntetiske respondenter: De er for ”glatte”. For enige med sig selv. For dårlige til at gengive den variation, uenighed og friktion, som kendetegner rigtige mennesker. Og det er ofte her, at det interessante ligger, vil vi mene. De store tendenser kender vi – men hvor er nuancerne, hvor er det nye, hvor er det spændende?
Bisbee et al. (2024) og Brand et al. (2024) viser begge, at svarvariationen er lavere i syntetiske data end i rigtige surveys. Argyle et al. (2023) peger på, at aggregerede mønstre i nogle tilfælde kan ligne menneskelige svar – men netop kun på aggregatniveau. Når man ser på individer og subgrupper, bliver billedet langt mindre overbevisende. Wang et al. (2025) dokumenterer en endnu mere foruroligende tendens: Syntetiske respondenter misrepræsenterer demografiske grupper ved at fremstille dem, som dominerende samfundsgrupper forestiller sig dem – ikke nødvendigvis, som grupperne forstår sig selv. Qu & Wang (2024) viser tilsvarende, at performance varierer markant på tværs af subgrupper og lande, hvilket skaber en reel risiko for både mis- og underrepræsentation. Og Peng et al. 2026 som fokuserer på ”digital twins” peger i samme retning: På tværs af 164 outcomes havde de digitale tvillinger lavere variation end mennesker i 154 tilfælde, og præcisionen var samtidig skævt fordelt, så nogle grupper – særligt mere veluddannede, mere velstillede og mere moderate deltagere – blev repræsenteret bedre end andre (Peng et al. 2026). Alt sammen ting vi ville finde problematiske ved andre dataindsamlinger – og som selvfølgelig også er problematiske her. Måske endda mere problematiske, da vi har markant sværere ved at validere vores resultater.
”Brandolinis principle” og valideringsproblematikken
Der er et begreb i epistemologien, der hedder Brandolinis princip – eller mere rammende: the bullshit asymmetry principle. Det lyder sådan her: Det kræver mere energi at gendrive nonsens – eller bullshit – end at producere det. Bullshit skal her forstås i en Frankfurts forstand: information der produceres uden hensyntagen til sandheden.
Jeg nævner det, fordi det har en ubehagelig relevans for syntetisk data. Det er hurtigt at generere 1.000 syntetiske respondenter. Det er langt sværere at eftervise, om de overhovedet siger noget sandt. Problemet er asymmetrien mellem produktion og validering. Syntetisk data er billige at producere, men valideringen en gordisk knude.
Der er flere årsager til, at validering af syntetiske respondenter er så vanskelig. En central udfordring er, at kombinationen af målgrupper, mulige spørgsmål og udvikling over tid skaber et nærmest uendeligt valideringsrum. I praksis betyder det, at man sjældent kan sige noget meningsfuldt om kvaliteten i netop ens specifikke undersøgelsesspørgsmål uden at sammenligne med data fra rigtige mennesker – og dermed forsvinder hele rationalet bag brugen af syntetiske data.
Samtidig bygger syntetiske respondenter ikke på en klassisk stikprøvelogik fra survey-forskningen, hvor vi har et robust og veldokumenteret statistisk fundament, som gør det muligt at generalisere fra en stikprøve til en population og beregne usikkerheder. Syntetiske respondenter udtrækkes nemlig ikke som en stikprøve, men genereres via. en sprogmodel. Derfor kan man heller ikke uden videre anvende statistikkens normale værktøjer til at vurdere usikkerhed, repræsentativitet og generaliserbarhed.
Det gør validering og valideringstilgange til et åbent spørgsmål. I Epinion anvender vi bestemte LLM-baserede tilgange til at analysere eks. store mængder tekst, og selv her – hvor LLMer demonstrerer markant bedre performance – arbejder vi altid med et valideringsframework. Det kan du læse mere om her: AI kræver validering – ikke bare gode prompts.
Hvornår kan det give mening?
Syntetiske respondenter kan have deres berettigelse . De kan fx bruges i tidlig konceptudvikling (så længe det ikke er ”døde laks”), pilottests, metodeudvikling, hypoteseafprøvning og som et internt redskab til at udfordre eller stressteste eksisterende indsigter. Syntetiske respondenter performer formentlig bedst, når populationen er veldefineret, når der findes solid historisk viden, og når formålet er at kvalificere en analyse – ikke at erstatte den.
Men grænsen nås hurtigt, når beslutningsvigtigheden stiger.
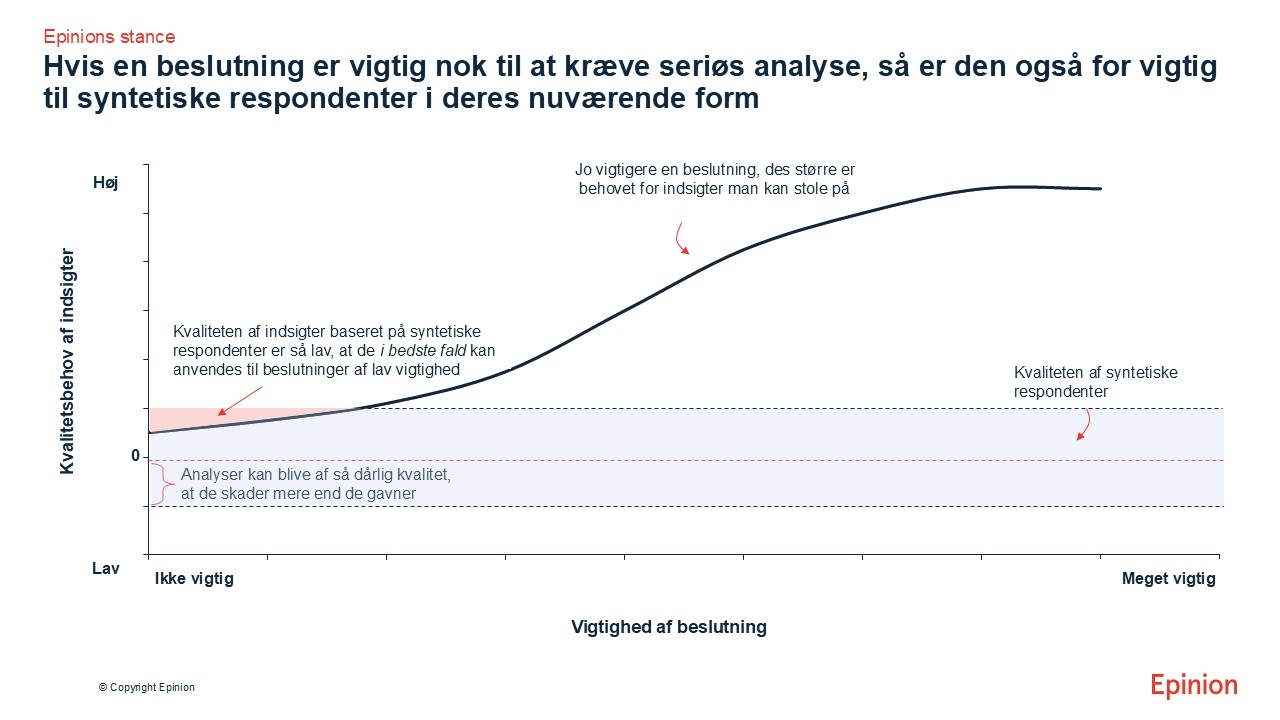
Epinions anbefaling er derfor:
- Undgå syntetiske respondenter til vigtige beslutninger
- Brug andre, mere gennemsigtige low-cost-metoder, når beslutningen er mindre vigtig
- Brug AI til at forbedre processerne rundt om data frem for at erstatte selve datagrundlaget
Det sidste er værd at understrege. AI er stærk, når den hjælper os med at arbejde bedre med data: søge, strukturere, opsummere, kode, ekstra kvalitetssikring, tekstanalyse. AI er mindre overbevisende, når den bliver gjort til erstatning for de mennesker, vi faktisk ønsker at forstå. Hvis man vil afprøve det, kan man stille sig selv et par spørgsmål, inden man går videre:
- Hvad er modellen trænet på – og hvad er den ikke trænet på? Og kan det gøre, at vi får forkerte svar?
- Hvordan vil vi validere, at de syntetiske svar faktisk afspejler virkelige svar? Og hvor omkostningstungt er det?
- Hvad mister vi, hvis den population, vi forsøger at simulere, er i bevægelse? Risikerer vi at få et svar fra fortiden – ikke om fremtiden?
Hvis I ikke kan svare klart på alle tre, bør I sandsynligvis overveje noget andet.
Konklusion
Dødlaks-studiet lærte os, at overbevisende output ikke er det samme som valid evidens. Selv avancerede, individfodrede tvillinger er endnu ikke tæt nok på mennesker til at kunne bære vigtige beslutninger. Derfor handler vores position ikke om teknologiforskrækkelse. Faktisk vil jeg sige, at hvis vi er noget, er vi mere teknologibegejstrede. Men vi skal altid være kritisk tænkende. Og i det her tilfælde fylder den del mere end begejstring.
……………………….
Om forfatterne
Bag denne artikel står Allan Toft Hedegaard Knudsen, der leder Epinions Data Science & Analytics-hub, og hans to kollegaer Thomas Skaalum Bargisen og Simon Emil Simmelkjær Andersen. Teamet arbejder i krydsfeltet mellem “AI, analyse og rådgivning” med fokus på, hvordan analyse- og rådgivningsbranchen kan anvende særligt store sprogmodeller på nye måder: Hvordan vi kan bruge de bedste ting fra data science, computervidenskab og samfundsvidenskab sammen med ny teknologi indenfor AI. De fokuserer særligt på at anvende store sprogmodeller i interne arbejdsgange og i eksterne kundeleverancer – men altid med øje for, at kvaliteten ikke kompromitteres.



……………………….
Referencer:
Argyle, L. P., E. C. Busby, N. Fulda, J. R. Gubler, C. Rytting, and D.Wingate. 2023. “Out of One, Many: Using Language Models to Simulate Human Samples.” Political Analysis: 1–15.
Bennett, C. M., Baird, A. A., Miller, M. B., & Wolford, G. L. (2010). Neural correlates of interspecies perspective taking in the post-mortem Atlantic Salmon: An argument for multiple comparisons correction. Journal of Serendipitous and Unexpected Results, 1(1), 1–5. Diss forskere fokusere mere på, at de metoder, man anvender med fMRI-scanniner skal foretages med “multiple comparison”-korrektion – men pointen illusteres med netop et overbevisende output fra en fMRI-scanning.
Bisbee, J., Clinton, J. D., Dorff, C., Kenkel, B., & Larson, J. M. (2024). Synthetic Replacements for Human Survey Data? The Perils of Large Language Models. Political Analysis, 32(4), 401–416.
Brand, J., Israeli, A., & Ngwe, D. (2023). Using LLMs for market research. Harvard Business School Marketing Unit Working Paper, (23-062).
Christian, Brian: The Alignment Problem – how can machines learn human values? (2021)
Peng, T., Gui, G., Brucks, M., Merlau, D. J., Fan, G. J., Ben Sliman, M., Johnson, E. J., Althenayyan, A., Bellezza, S., Donati, D., Fong, H., Friedman, E., Guevara, A., Hussein, M., Jerath, K., Kogut, B., Kumar, A., Lane, K., Li, H., Morwitz, V., Netzer, O., Perkowski, P., & Toubia, O. (2026). Digital twins as funhouse mirrors: Five key distortions. arXiv. Preprint.
Wang, A., Morgenstern, J. & Dickerson, J.P. Large language models that replace human participants can harmfully misportray and flatten identity groups. Nat Mach Intell 7, 400–411 (2025).
Quattrociocchi, W., Capraro, V., & Perc, M. (2025). Epistemological fault lines between human and artificial intelligence. arXiv.
Qu, Y., Wang, J. Performance and biases of Large Language Models in public opinion simulation. Humanit Soc Sci Commun 11, 1095 (2024).





